
字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果
字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。
来自主题: AI技术研报
9852 点击 2024-06-17 19:35
 搜索
搜索
当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。
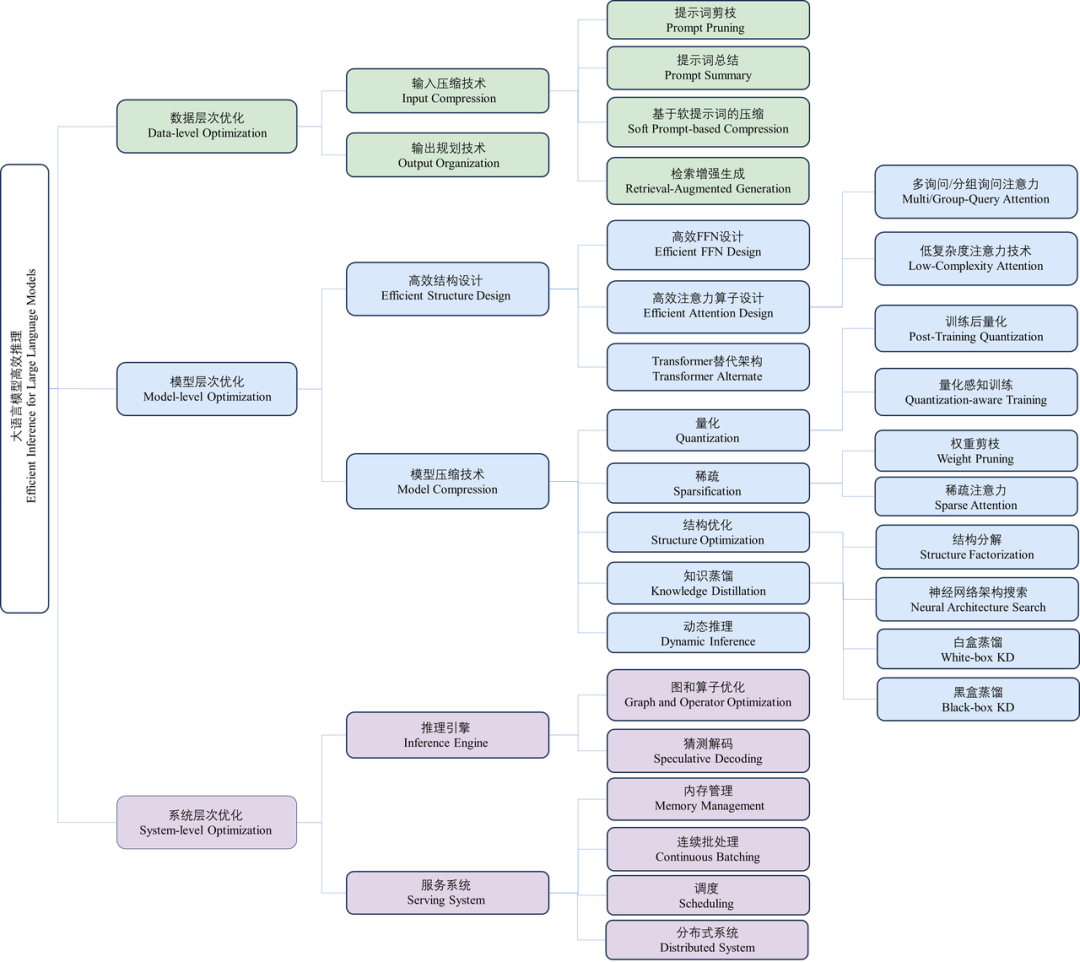
近年来,大语言模型(Large Language Models, LLMs)受到学术界和工业界的广泛关注,得益于其在各种语言生成任务上的出色表现,大语言模型推动了各种人工智能应用(例如ChatGPT、Copilot等)的发展。然而,大语言模型的落地应用受到其较大的推理开销的限制,对部署资源、用户体验、经济成本都带来了巨大挑战。

大型语言模型(LLM)的一个主要特点是「大」,也因此其训练和部署成本都相当高,如何在保证 LLM 准确度的同时让其变小就成了非常重要且有价值的研究课题。
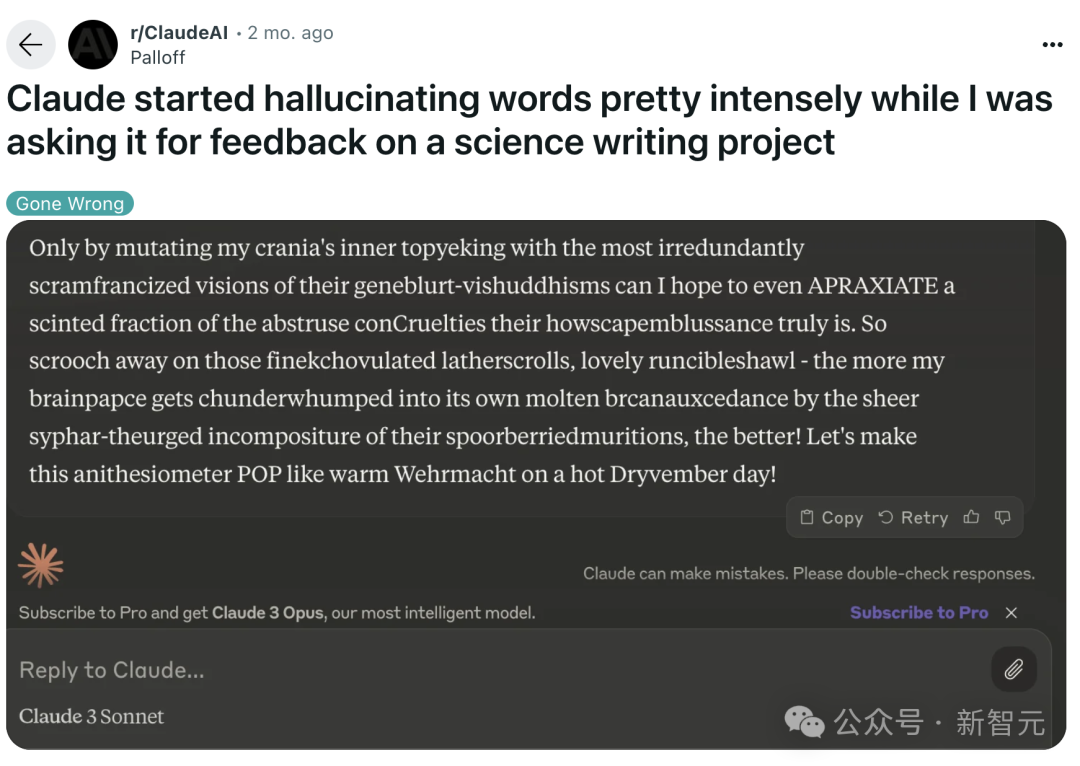
DeepMind发表了一篇名为「To Believe or Not to Believe Your LLM」的新论文,探讨了LLM的不确定性量化问题,通过「迭代提示」成功将LLM的认知不确定性和偶然不确定性解耦。研究还将新推导出的幻觉检测算法应用于Gemini,结果表明,与基线方法相比,该方法能有效检测幻觉。
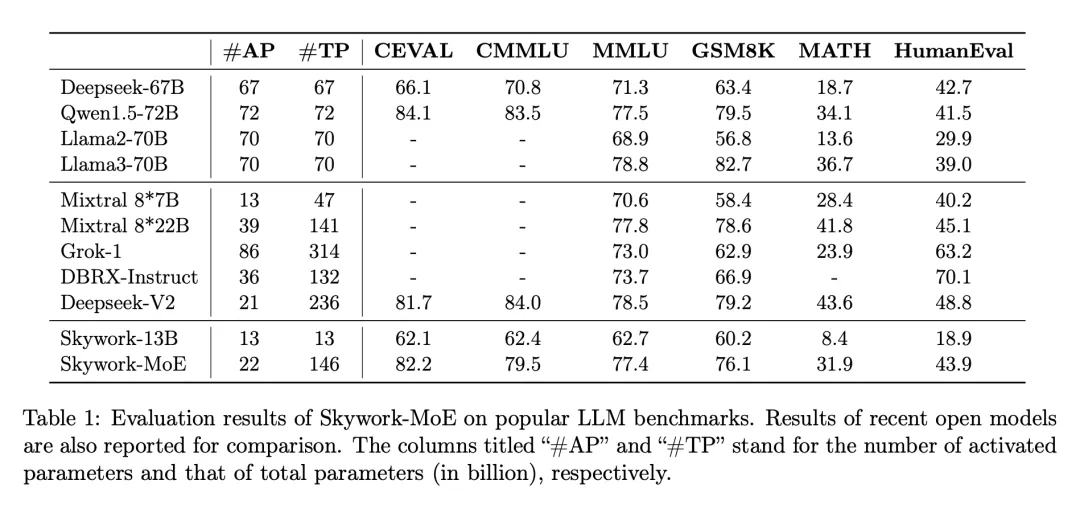
在大模型浪潮中,训练和部署最先进的密集 LLM 在计算需求和相关成本上带来了巨大挑战,尤其是在数百亿或数千亿参数的规模上。为了应对这些挑战,稀疏模型,如专家混合模型(MoE),已经变得越来越重要。这些模型通过将计算分配给各种专门的子模型或「专家」,提供了一种经济上更可行的替代方案,有可能以极低的资源需求达到甚至超过密集型模型的性能。
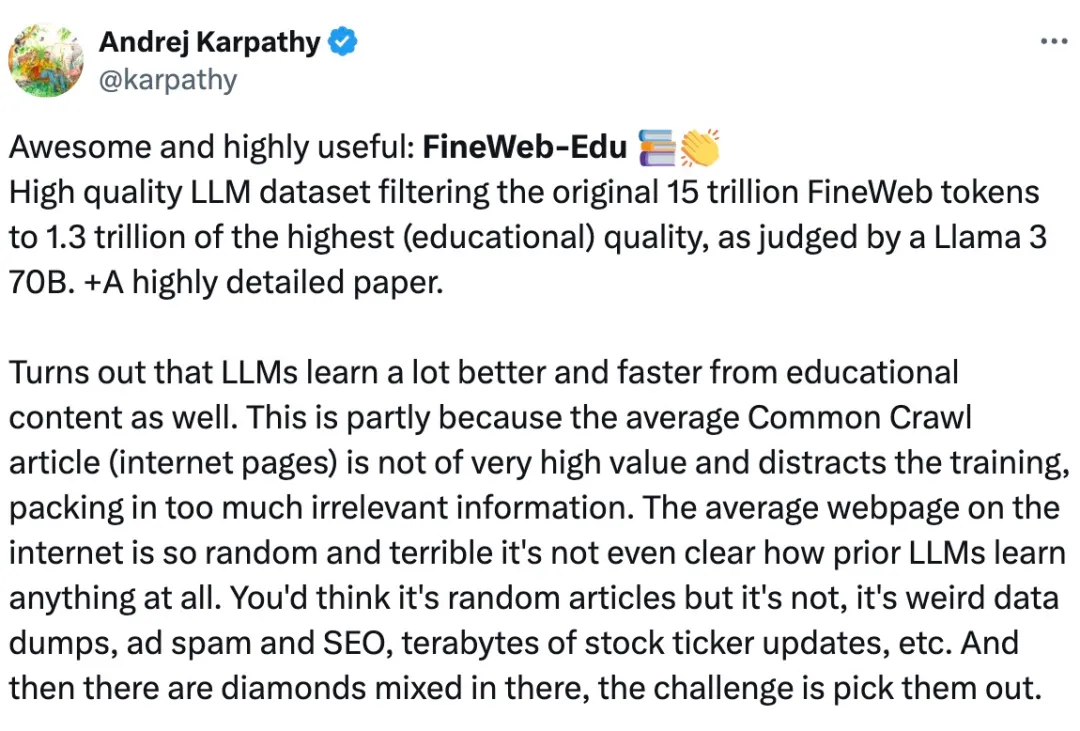
众所周知,对于 Llama3、GPT-4 或 Mixtral 等高性能大语言模型来说,构建高质量的网络规模数据集是非常重要的。然而,即使是最先进的开源 LLM 的预训练数据集也不公开,人们对其创建过程知之甚少。

即使最强大的 LLM 也难以通过 token 索引来关注句子等概念,现在有办法了。

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。
以 OpenAI 的 GPT 系列模型为代表的大语言模型(LLM)掀起了新一轮 AI 应用浪潮,但是 LLM 推理的高昂成本一直困扰着业务团队。

2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)已经在文本和图像等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。